本系列文章將深入淺出地探討機器學習(ML)與深度學習(DL)領域的經典與當前流行的模型,涵蓋從基礎概念到實作應用。
內容重點如下:
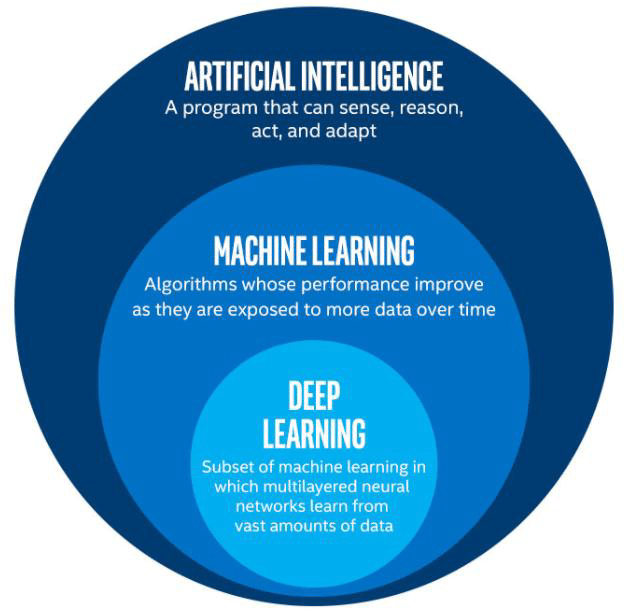
簡單來説,人工智慧是我們想要達成的目標,機器學習是我們達成目標的的手段之一,而深度學習則是機器學習的其中一種方法。
Handwritten Text Recognition using Deep Learning (CNN & RNN)
AI這個詞匯其實在1950年代就已經出現了,所以AI並不是什麼非常新潮的東西。如果有寫過程式的人應該都知道,我們在寫程式的時候,會寫一些規則去判斷處理一些事情,這個行爲我們將它成爲hand-crafted rules,有的時候一些大公司有辦法靠大量的人力來手寫數以萬計的這些規則,讓他們的產品包裝的很像一個AI產品,但是這樣的方法真的可行嗎?會不會導致說你寫出來的程式,其實是不那麼好維護,也很容易出問題,而且有的時候要達成某個功能的規則其實不是那麼好寫,你可能會需要一個非常非常複雜的規則才可以達到你要的效果,那顯然不是人能寫出來的,所以我們現在才會希望讓機器有自我學習的能力。
至於我們要怎麼讓機器有學習的能力?試想一下,一般上來説我們希望一個function給他一個input,它會吐出一個output:你可以給它一段音頻,它告訴你這段話在説什麼;給它一個貓跟狗的照片,它告訴你這是貓還是狗;如果有看過台大教授李宏毅的Youtube課程的話,就知道機器學習在做的事就是尋找一個function的過程,你要讓機器具備根據你提供給它的資料,去尋找出我們要的function的能力。
要怎麼讓機器找出我們要的function呢?我們可以遵循一個framework的三大步驟:
看到這邊,先恭喜你已經學會了Machine Learning了!但是我相信對於初學者而言,哪怕是看到這邊,依然是一頭霧水。這樣的情況就好像大部分人剛開始學習寫程式時,成功印出"Hello World!"一樣,體驗到了寫程式是怎麼一回事,但又還沒有建立起寫程式是怎麼一回事的相關概念,所以接下來,我將要介紹關於Machine Learning的一些基礎概念。
我喜歡把知識比喻成一棵大樹,框架就是樹幹。當我們想了解一件事時,不妨先問問樹幹我們想要瞭解的知識在哪裡。一般細節像是樹葉,很容易找到,但樹幹的結構才是整棵樹的精髓。就像我們有時候會去聽一些技術大咖的演講或課程,他們可能記不清每一片葉子(細節),但對樹幹的結構(框架)卻了然於心。要想學好Machine Learning,就要從你想要解什麼任務開始説起,當你知道你要解什麼任務之後,你就要思考用什麼樣的方式去解你的任務,然後,你還要根據你現有的資料來判斷哪一種方法最適合用來達成你的目標。你可能會覺得這件事情太過抽象,但是往下看,你就會知道這個流程其實是非常簡單的。
Regression
迴歸任務旨在預測一個連續的數值。換句話說,我們希望找到一個函數,使其輸入一些特徵時能夠輸出對應的標量(例如溫度、距離、價格等)。例如,小明的朋友小張每次約會都會遲到,且遲到的時間有一定的波動。小明希望根據小張過去一年的遲到記錄,預測他明天會遲到多久。這就是一個典型的迴歸問題,我們要通過分析歷史數據來預測一個具體的連續時間(如分鐘或小時)。
Classification
分類任務的目的是將輸入數據分配到一個預定義的類別中。它不僅限於二元分類(如是否垃圾郵件),也可以應用於多類別分類(如圖片中是貓還是狗,或者一個手寫數字是0到9中的哪個)。舉例來說,如果你想開發一個程式來判斷電子郵件是否是垃圾郵件,或者想根據天氣數據預測小張明天是否會遲到,這些問題就屬於分類問題。除此之外,分類任務也能應用於更複雜的情境,例如在自然語言處理中,模型可以判斷一篇文章屬於哪一個版面(如體育、娛樂、財經等)。
Structured Learning
結構化學習(Structured Learning)處理的是更複雜的預測問題,這些問題的輸出具有內部結構或依賴關係。與單純的迴歸或分類不同,結構化學習模型同時預測一組相關的變量,這些變量之間可能具有某種關聯性。常見的應用包括自然語言處理中的語法分析、機器翻譯、圖像語義分割等。在這些情境中,模型需要不僅考慮單個輸出的正確性,還需要理解和處理輸出之間的相互關係。
Linear Model
線性模型是機器學習中最基本的一類模型。它假設輸入變量和輸出變量之間具有線性關係。在迴歸問題中,線性模型會嘗試找到最佳擬合的直線,而在分類問題中,線性分類器(如邏輯回歸)用於找到分割不同類別的超平面。這類模型計算效率高,適合處理線性關係的數據。
Deep Learning
深度學習是基於神經網絡的技術,尤其在處理複雜模式識別問題時非常強大。通過大量的層級和數據來學習數據中的隱藏特徵,深度學習已被廣泛應用於圖像分類、語音識別、自然語言處理等領域。與傳統模型相比,深度學習的關鍵優勢在於它能自動地學習高層次特徵。
Decision Trees
決策樹是一種基於分支結構的模型,它通過對數據特徵進行逐層劃分來進行預測。每個節點代表一個特徵,每條邊代表特徵的可能值,葉節點則表示最終的預測結果。決策樹直觀易解釋,並且能處理類別型和連續型數據。
K-Nearest Neighbors (KNN)
KNN算法基於「相似數據點的預測結果相似」的原則。當進行預測時,KNN會找到與目標數據點距離最近的K個數據點,然後根據它們的標籤進行投票(分類問題)或平均(迴歸問題)來決定預測結果。KNN非常簡單,但計算量大,尤其是在處理大型數據集時。
Support Vector Machines (SVM)
支持向量機是一種分類算法,它試圖找到分隔不同類別的最佳超平面,這個超平面可以最大化類別之間的間隔。SVM對於高維數據非常有效,並且可以通過核函數處理非線性問題。
Naïve Bayes
Naïve Bayes是一種基於條件概率的分類算法,它假設每個特徵是獨立的,並且每個特徵對結果的影響都是相同的。儘管這一假設在現實中往往不成立,但樸素貝葉斯模型通常表現出意想不到的強大效果,特別是在文本分類問題中。
Gaussian Mixtures
高斯混合模型是一種基於概率分佈的無監督學習算法,它假設數據來自於多個高斯分佈的混合。每個高斯分佈對應於數據中的一個簇,通過最大化似然估計來確定這些分佈的參數。它廣泛應用於聚類分析。
……
Supervised Learning
監督學習是一種利用帶有標籤的訓練數據進行學習的過程。模型會根據輸入和對應的正確輸出進行學習,並嘗試對新數據進行預測。這種學習方法主要應用於分類和迴歸問題,比如垃圾郵件檢測或房價預測。
Unsupervised Learning
非監督學習則不依賴於標籤數據,模型需要從數據中自行發現隱藏的結構或模式。常見的無監督學習算法包括聚類(如K-means)和 Dimensionality Reduction,它們廣泛應用於數據探索、特徵提取或數據壓縮等領域。
Semi-supervised Learning
半監督學習介於監督學習和無監督學習之間,通常利用少量標籤數據和大量無標籤數據來訓練模型。這種方法特別適合標籤數據難以獲取而無標籤數據豐富的情境,比如圖像標籤或醫療數據分析。
Transfer Learning
Transfer Learning是指在一個任務中學到的知識被應用到另一個相關任務中的技術。這在處理少量數據或快速學習新問題時非常有效,特別是在圖像識別和自然語言處理等領域,已經訓練好的深度學習模型可以遷移到新的應用上。
Reinforcement Learning
強化學習是一種基於試探和回饋的學習方式,模型通過在環境中不斷試探來獲取最大化的回報。每次行為會對環境造成影響,模型則根據這些影響來更新自己的行為策略。這種學習方式常用於遊戲AI、自動駕駛車輛等需要連續決策的領域。